The background sampling includes code based on a Geographic Information Systems stack exchange answer by user Spacedman.
Usage
prep_sdm(
this_taxa = NULL,
out_dir = FALSE,
return_val = "path",
presence,
pres_col = "pa",
pres_val = 1,
pres_crs = 4326,
pres_x = "long",
pres_y = "lat",
pred_limit = TRUE,
limit_buffer = 0,
pred_clip = NULL,
predictors,
max_na_predictor_prop = 0.05,
is_env_pred = TRUE,
terra_options = NULL,
cat_preds = NULL,
cat_preds_max_levels = 32,
num_bg = 10000,
new_bg_test = TRUE,
bg_prop_cells = 0,
many_p_prop = 2,
folds = 5,
spatial_folds = TRUE,
repeats = 1,
folds_div = seq(2.1, to = 4.5, length.out = folds),
area_prop = 0.9,
max_repeat_corr = 0.9,
min_fold_n = 8,
hold_prop = 0.3,
stretch_value = 10,
dens_res = 1000,
reduce_env_thresh_corr = 0.9,
reduce_env_quant_rf_imp = 0.2,
do_gc = FALSE,
force_new = FALSE
)Arguments
- this_taxa
Character. Name of taxa. Only used to print some messages. Ignored if NULL
- out_dir
FALSE or character. If FALSE the result of prep_sdm will be saved to a temporary folder. If character, a file 'prep.rds' will be created at the path defined by out_dir.
- return_val
Character: "object" or "path". Both return a named list. In the case of "path" the named list is simply list(prep = out_dir). Will be set to "object" if
out_diris FALSE.- presence
Dataframe of presences with columns
pres_xandpres_y.- pres_col
Character. Name of column in
presencethat defines presence (1) or absence (0). Optional if only presence data is supplied.- pres_val
Numeric. Values in
pres_colthat represent presences. Optional if only presence data is supplied.- pres_crs
Anything that will return a legitimate crs when passed to the crs attribute of
sf::st_transform()orsf::st_as_sf().- pres_x, pres_y
Character. Name of the columns in
presencethat have the x and y coordinates- pred_limit
Limit the background points and predictions? Can be
TRUE(usepresenceto generate a minimum convex polygon to use as a limit. Not recommended as the points inpresencehave usually been filtered to very accurate spatial reliability and thus may be missing a large number of legitimate records);FALSE(the full extent of the predictors will be used); path to existing .parquet to use; or sf object.- limit_buffer
Numeric. Apply this buffer to
pred_limit. Only used ifpred_limitisTRUE. Passed to thedistargument ofsf::st_buffer().- pred_clip
sf. Optional sf to clip the pred_limit back to (e.g. to prevent prediction into ocean).
- predictors
Character. Vector of paths to predictor
.tiffiles.- max_na_predictor_prop
Proportion. A predictor will be dropped if the proportion of presences with
NAvalues for that predictor exceedsmax_na_predictor_prop- is_env_pred
Logical. Does the naming of the directory and files in
predictorsfollow the pattern required byenvRaster::parse_env_tif()?- terra_options
Passed to
terra::terraOptions(). e.g. list(memfrac = 0.6)- cat_preds
Character. Vector of predictor names that are character.
- num_bg
Numeric. How many background points?
- new_bg_test
Logical. Use an entirely new set of background points for testing the full model?
- bg_prop_cells
Proportion. Ensure
num_bgreachesprop_cells(background points as a proportion of the number of non-NA cells within the predict/calibration boundary).- many_p_prop
Numeric. Ensure the number of background points is at least
many_p_prop * number of presences. e.g. If there are more than 5000 presences and num_bg is set at10000andmany_p_propis2, then num_bg will be increased tomany_p_prop * nrow(presences)- folds
Numeric. How many folds to use in cross validation? Will be adjusted downwards if number of presences do not support
folds * min_fold_n- spatial_folds
Logical. Use spatial folds? Even if
TRUE, can resort to non-spatial cv if presences per fold do not meetmin_fold_nor there are not enough presences to support more than one fold.- repeats
Numeric. Number of repeated cross validations.
- folds_div
Numeric. The square root of the an area (see
area_prop) is divided by this value before being passed to theblock_distargument ofblockCV::cv_spatial(). If using cross validation,fold_divmust be of the same length as1:folds. Ignored if not using spatial_folds.- area_prop
Proportion. What proportion of the kernel density from presence points should be included in a minimum convex polygon (mcp) for use with
folds_div? Passed (as %) to theadehabtiatHR::kernel.area()percentargument.- max_repeat_corr
Numeric. Maximum correlation allowed between the folds of any two spatial folds before one of the correlated folds will be set to non-spatial and the folds reallocated. Correlation tested on presences only.
- min_fold_n
Numeric. Sets both minimum number of presences, and, by default, the minimum number of presences required for a model.
- hold_prop
Numeric. Proportion of data to be held back from training to use to validate the final model.
- stretch_value
Numeric. Stretch the density raster to this value.
- dens_res
NULLor numeric. Resolution (in metres) of density raster. Set toNULLto use the same resolution as the predictors.- reduce_env_thresh_corr
Numeric. Threshold used to flag highly correlated variables. Set to 1 to skip this step. If > 0, highly correlated and low importance variables will be removed. In the case of highly correlated pairs of variables, only one is removed.
- reduce_env_quant_rf_imp
Numeric. Bottom quantile of importance values to drop.
- do_gc
Logical. Run
base::rm(list = ls)andbase::gc()at end of function? Useful when running SDMs for many, many taxa, especially if done in parallel.- force_new
Logical. If outputs already exist, should they be remade?
Value
If return_val is "object" a named list. If return_val is "path"
a path to the saved file. If out_dir is a valid path, the 'full
result' (irrespective of return_val) is also saved to
fs::path(out_dir, "prep.rds"). The 'full result' is a named list with
elements:
log:
a log of (rough) timings and other information from the process
abandoned:
Logical indicating if the sdm was abandoned. If abandoned is TRUE, some list elements may not be present
presence_ras:
tibble with two columns ('x' and 'y') representing unique cell centroids on the predictors at presences supplied in argument
presence
predict_boundary:
sf used to limit the background points and used by
predict_sdm()to generate the 'mask'ed outputi.e. the predict boundary is both callibration and predict boundary
bg_points:
sf of cell centroids representing unique cell centroids for background points
folds
data.frame with columns:
pa: presence (1) or absence/background (0)xandy: cell centroids for each presence and absencefold: the spatial fold to which the row belongsa column with values for each of
predictorsatxandy
spatial_folds_used:
logical indicating if spatial folds were used. This may differ from the
spatial_foldsargument provided toprep_sdm()if an attempt to use spatial folds failed to meet desiredfoldsandmin_fold_n
correlated:
list with elements as per
envModel::reduce_env(), or, ifreduce_envisFALSE, a list with elementsremove_envwhich is empty, andenv_varandkeep, which both contain the names of all predictors. The coordinate reference system of any outputs is the same crs aspredictors.
Details
If memory is an issue, try adjusting terra_options and/or do_gc.
To help build the density raster for assigning background points, 'absence'
data can be supplied in presence as 0 values. e.g. For a bird, absence
data might be generated from other sites where birds were recorded but
this_taxa was not. Note that these 0 'records' are not used directly as
background points but instead are used to improve the sampling density raster
against which background points are assigned.
Examples
library("tmap")
out_dir <- file.path(system.file(package = "envSDM"), "examples")
# data ---------
hold_prop <- c(0, 0.3)
stretch <- c(10, 30)
spatial_folds <- c(T, F)
sdms <- expand.grid(hold_prop = hold_prop, stretch = stretch, spatial_folds = spatial_folds)
data <- fs::dir_ls(out_dir, regexp = "\\.csv$") |>
tibble::enframe(name = NULL, value = "path") |>
dplyr::mutate(taxa = gsub("\\.csv", "", basename(path))) |>
dplyr::cross_join(sdms) |>
tidyr::unite(col = "out_dir"
, c(taxa, tidyselect::any_of(names(sdms)))
, sep = "__"
, remove = FALSE
) |>
dplyr::mutate(out_dir = fs::path(dirname(path), out_dir)
, out_mcp = fs::path(out_dir, "mcp.parquet")
, dens_ras = fs::path(out_dir, "density.tif")
, prep = fs::path(out_dir, "prep.rds")
, tune = fs::path(out_dir, "tune.rds")
, full_run = fs::path(out_dir, "full_run.rds")
, pred = fs::path(out_dir, "pred.tif")
, thresh = fs::path(out_dir, "thresh.tif")
)
# save here for use in other examples
saveRDS(data, fs::path(out_dir, "data.rds"))
# predictors -------
preds <- fs::dir_ls(fs::path(out_dir, "tif"))
# clip --------
# make a clip boundary so mcps stay terrestrial
clip <- terra::as.polygons(terra::rast(preds)[[1]] > -Inf) |>
sf::st_as_sf()
# mcps --------
purrr::pwalk(list(data$path
, data$out_mcp
)
, \(x, y) envDistribution::make_mcp(readr::read_csv(x), y, pres_x = "cell_long", pres_y = "cell_lat"
, clip = clip
, dens_int = 50000
)
)
# prep -----------
# use the just created mcps (this allows using, say, a different spatial reliability threshold for the mcps)
future::plan(future::multisession())
furrr::future_pwalk(list(data$taxa
, data$out_dir
, data$path
, data$out_mcp
, data$hold_prop
, data$stretch
, data$spatial_folds
)
, function(a, b, c, d, e, f, g) prep_sdm(this_taxa = a
, out_dir = b
, presence = readr::read_csv(c)
, pres_x = "cell_long"
, pres_y = "cell_lat"
, predictors = preds
, is_env_pred = FALSE
, pred_limit = d
, limit_buffer = 10000
, min_fold_n = 5
, folds = 5
, spatial_folds = g
, repeats = 5
, hold_prop = e
, dens_res = 1000 # ignored as decimal degrees preds
, reduce_env_thresh_corr = 0.95
, reduce_env_quant_rf_imp = 0.2
, stretch_value = f
, num_bg = 100 # way too few
, bg_prop_cells = 0.01 # but ensure there are at least 1% of cells with backgrounds
#, force_new = TRUE
)
)
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0__10__TRUE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0.3__10__TRUE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0__30__TRUE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0.3__30__TRUE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0__10__FALSE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0.3__10__FALSE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0__30__FALSE.
#> 103 incoming presences
#> Rows: 103 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for chg
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/chg__0.3__30__FALSE.
#> 103 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0__10__TRUE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0.3__10__TRUE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0__30__TRUE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0.3__30__TRUE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0__10__FALSE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0.3__10__FALSE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0__30__FALSE.
#> 677 incoming presences
#> Rows: 677 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for mjs
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/mjs__0.3__30__FALSE.
#> 677 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0__10__TRUE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0.3__10__TRUE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0__30__TRUE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0.3__30__TRUE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0__10__FALSE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0.3__10__FALSE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0__30__FALSE.
#> 5 incoming presences
#> Rows: 5 Columns: 2
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> dbl (2): cell_lat, cell_long
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> prep for wjb
#> out_dir is /tmp/RtmpmQhxEJ/temp_libpath1dfd606e7eb11f/envSDM/examples/wjb__0.3__30__FALSE.
#> 5 incoming presences
future::plan(future::sequential())
# example of 'prep'
prep <- rio::import(data$prep[[1]], trust = TRUE)
names(prep)
#> [1] "abandoned" "finished" "log" "this_taxa"
#> [5] "epsg_in" "epsg_out" "original" "pa_ras"
#> [9] "presence_ras" "predict_boundary" "bg_points" "env"
#> [13] "testing" "training" "prep_fold_corr" "reduce_env"
# variables to remove prior to SDM
prep$reduce_env$remove
#> [1] "bio04" "bio07" "bio08" "bio09" "bio12" "bio13"
#> [7] "bio16" "bio17" "bio18" "bio19" "cell" "cell_lat"
#> [13] "cell_long" "fold" "id" "pa" "x" "y"
# spatial blocks used
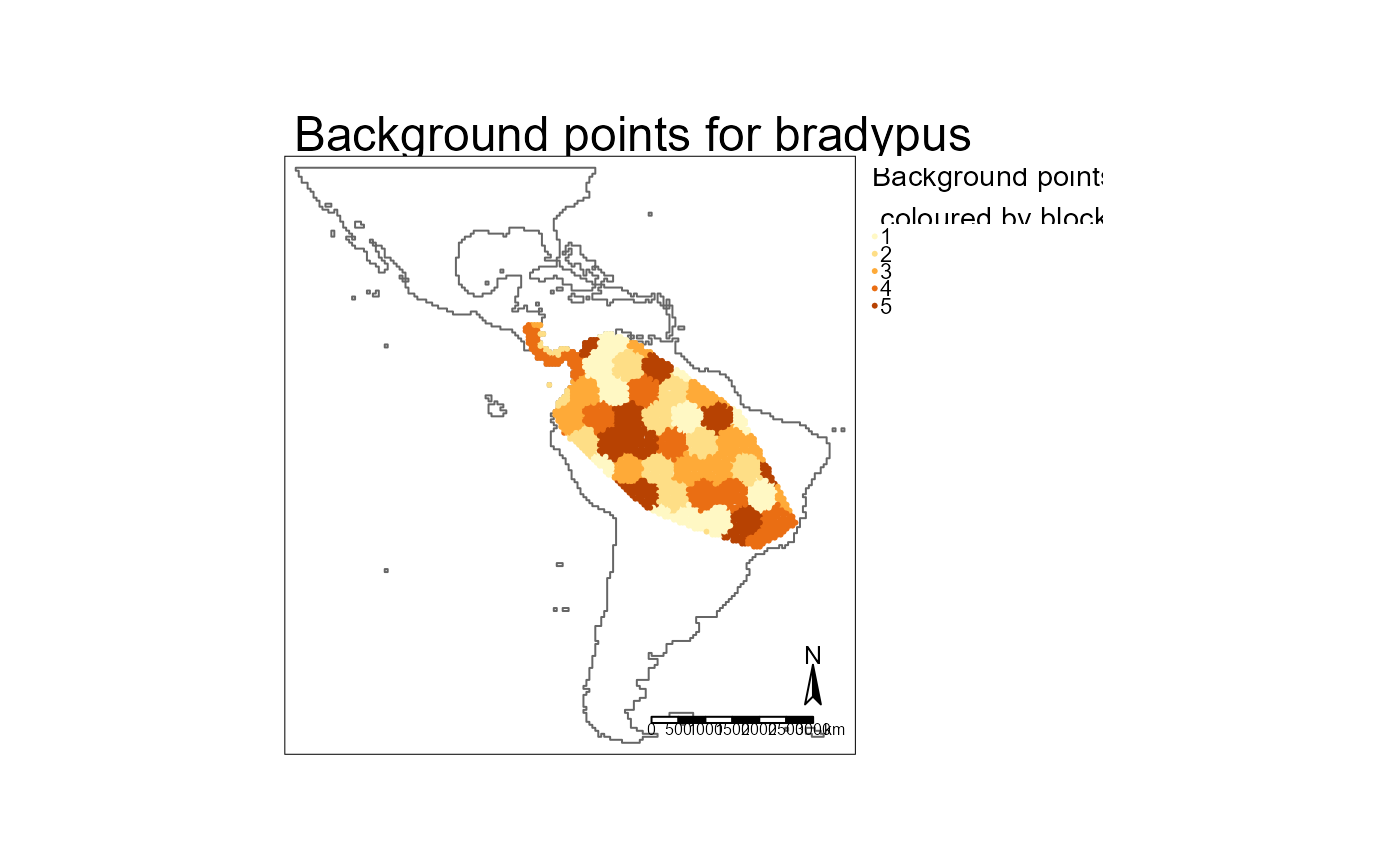
purrr::map(prep$training$cv_spatial, \(x) x$result$blocks |> dplyr::mutate(size = paste0("size_", x$result$size))) |>
dplyr::bind_rows() |>
tm_shape() +
tm_borders(col = "size")
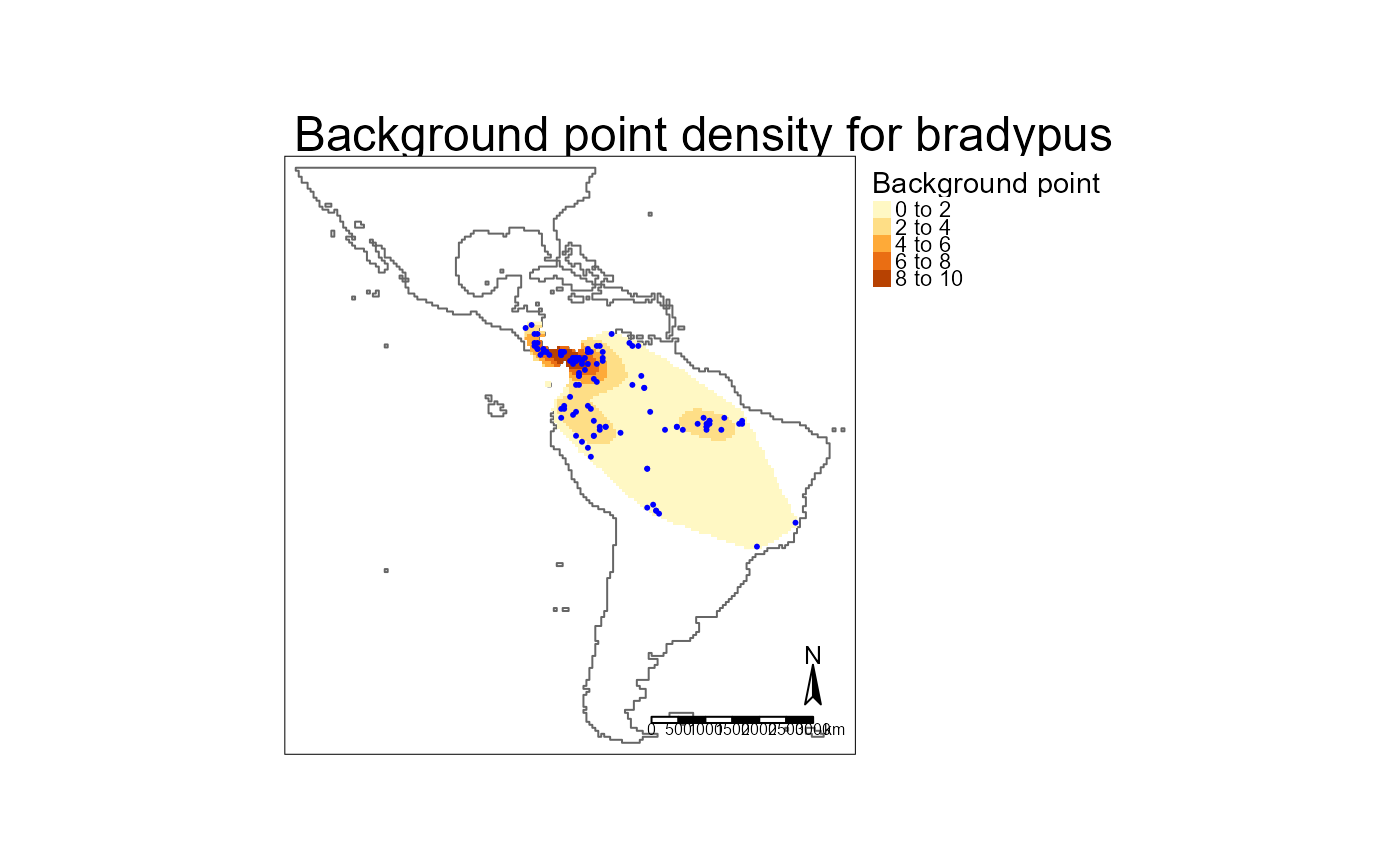 # Background points
if(require("tmap")) {
preps <- data$prep |>
purrr::map(readRDS)
b <- preps |>
purrr::map("bg_points") |>
purrr::set_names(data$stretch) |>
dplyr::bind_rows(.id = "stretch") |>
dplyr::mutate(stretch = as.numeric(stretch)
, type = "background"
)
p <- preps |>
purrr::map(\(x) sf::st_as_sf(x$presence_ras
, coords = c("x", "y")
, crs = x$epsg_out
)
) |>
purrr::set_names(data$stretch) |>
dplyr::bind_rows(.id = "stretch") |>
dplyr::mutate(stretch = as.numeric(stretch)
, type = "presence"
)
tm_shape(dplyr::bind_rows(b, p)) +
tm_dots(fill = "type"
, size = 0.05
) +
tm_facets(by = "stretch")
}
# Background points
if(require("tmap")) {
preps <- data$prep |>
purrr::map(readRDS)
b <- preps |>
purrr::map("bg_points") |>
purrr::set_names(data$stretch) |>
dplyr::bind_rows(.id = "stretch") |>
dplyr::mutate(stretch = as.numeric(stretch)
, type = "background"
)
p <- preps |>
purrr::map(\(x) sf::st_as_sf(x$presence_ras
, coords = c("x", "y")
, crs = x$epsg_out
)
) |>
purrr::set_names(data$stretch) |>
dplyr::bind_rows(.id = "stretch") |>
dplyr::mutate(stretch = as.numeric(stretch)
, type = "presence"
)
tm_shape(dplyr::bind_rows(b, p)) +
tm_dots(fill = "type"
, size = 0.05
) +
tm_facets(by = "stretch")
}